

KI Schutz und KI Sicherheit werden oft gleichgesetzt. Doch der eine schützt Menschen, der andere das System.
Chain of Thought und Reward Hacking zeigen, wie wichtig dieser Unterschied ist. Nur wer beides versteht, kann KI sicher entwickeln.
- 1. KI FAQ Glossar: KI Begriffe einfach erklärt
- 2, KI FAQ Glossar: 5 Fehlerquellen für einen Algorithmus, etc.
- 3. KI FAQ Glossar: Kompetenz, Literacy, Skills Guardrails, etc.
- 4. KI FAQ Glossar: AI Safety | KI Schutz (sie sind hier)
- KI Wissen kompakt – Strategie, Skills und Trends
In diesem Beitrag ist der Fokus auf die KI Schutz.
Das Inhaltsverzeichnis rechts bietet ihnen die Möglichkeitm zu den für sie interessanten Definitionen schnell vorzudringen (anklicken und sie sind dort).
Was ist der Unterschied zwischen KI Sicherheit und KI Schutz
KI Sicherheit und KI Schutz sind verwandt, aber nicht identisch.
KI Schutz bezieht sich auf die Rechte und Interessen der Menschen, die mit der KI arbeiten oder von ihren Entscheidungen betroffen sind. Es geht um Verantwortung, Fairness und den Schutz vor Schaden wie auch vor Diskriminierung und Fehlinformationen. Ziel ist es, Schäden, ethische Verstösse oder unbeabsichtigte Folgen zu vermeiden.
Zum Beispiel: Wie verhindern wir, dass KI falsche Infos liefert (z.B. wegen Hallucination), Jugendliche gefährdet oder bestimmte Gruppen benachteiligt?
KI Sicherheit hingegen zielt auf Bedrohungen ab, die das System selbst betreffen. Etwa Angriffe auf das Modell, Manipulation von Daten oder Sabotage durch Dritte.
Weitere Beispiele: Schutz vor Datenlecks, Hacking, Manipulation durch fehlerhafte Prompts (Prompt Injection).
Kurz: KI Sicherheit ist Vergleichbar mit IT Sicherheit oder Cybersecurity.
Kurz gesagt:
- KI Sicherheit schützt das System.
- KI Schutz schützt die Menschen.
Beide Perspektiven sind wichtig. Beim Aufbau einer KI Lösung müssen KI Sicherheit und KI Safety zusammen umgesetzt werden.
KI Security
Bei der KI Sicherheit oder AI Security geht es in erster Linie um die Sicherung von Systemen. Dabei stehen Vertraulichkeit, Integrität und Verfügbarkeit der Daten und Systeme im Vordergrund.
KI Sicherheit umfasst den Schutz vor unberechtigtem Zugriff (unauthorized access), Datenverletzungen (data breaches) und Störungen der KI Systeme, Modellen und Daten.
KI Schutz – AI Protection / Safety
Ziel von AI Safety, d.h. KI Schutz ist es, Risiken zu minimieren. Fehler in Algorithme (siehe die 5 Fehler Typen hier) können unbeabsichtigt Schaden anrichten. Sie entstehen oft bei der Programmierung.
KI Sicherheit oder KI Schutz umfasst auch Überlegungen zum menschlichen Wohlbefinden, zu ethischen Implikationen und gesellschaftlichen Werten was das KI Modell betrifft.
KI Schutz geht über die Grenzen der technischen Sicherheitsmassnahmen hinaus.
Unsicher bei KI-Schutz oder Audit?
Einfach melden – wir helfen weiter!
Chain of Thought
Chain-of-Thought fordert KI „reasoning“ (Begründungen oder Überlegungen) auf, Probleme Schritt für Schritt zu lösen. Sie zeigt gleichzeitig auf, wie die KI die Antwort auf eine Anfrage ausarbeitet.
Anthropic, Google, OpenAI und Elon Musks xAI gehören zu den Technologiekonzernen, die eine Technik namens „chain-of- thought“ entwickelt haben, mit der sie ihre AI Modelle auffordern, Probleme zu lösen.
Dieser Prozess hat wertvolle Erkenntnisse geliefert, die es den Technologieunternehmen ermöglichen, bessere KI Modelle zu entwickeln. Allerdings finden sie auch Beispiele für „Fehlverhalten“. Beispielsweise wenn ein generativer KI Chatbot eine endgültige Antwort liefert, die nicht mit der Art und Weise übereinstimmt, wie er die Antwort erarbeitet hat.
Diese Ungereimtheiten deuten darauf hin, dass sich die führenden KI Firmen nicht vollständig darüber im Klaren sind, wie generative KI Modelle zu ihren Schlussfolgerungen gelangen.
Sie haben zu einer breiteren Besorgnis darüber geführt, die Kontrolle über leistungsstarke KI Systeme zu behalten, vor allem auch deshalb, weil diese immer leistungsfähiger und autonomer werden.
Chain-of-Thought ist mehr als eine Technik. Sie öffnet ein Fenster ins Innenleben der KI. Sie zeigt wie ein Large Language Model (LLM) denkt und warum und wie die Entscheidungen entstehen.
Chain of Thought: Kürzer heisst präziser
Forscher von Meta und der Hebrew University fanden heraus, dass kürzere Denkketten grosse Sprachmodelle in 20 – 40 % der Fälle übertreffen. Das betrifft die Genauigkeit der Lösung, aber auch die Effizienz bei der Arbeit.
Kürzere Ketten brauchen ebenfalls bis zu 40 % weniger „thinking tokens“ (Denk Tokens). Das spart Rechenleistung, Energie und Kosten.
Kürzere Chain-of-Thought Audit
Nutzern der Chatbots von OpenAI und Anthropic (Claude) wird derzeit eine zusammengefasste Gedankenkette gezeigt. Diese schliesst eine detailliertere Aufschlüsselung aus, bei der schädliches Material entfernt wird.
KI Entwickler können den vollständigen Gedankengang sehen. Dies gibt ihnen die Möglichkeit, einzugreifen und das Modell so zu trainieren, dass es in Zukunft bessere Antworten liefert.

Glossar Teil 4 – KI Schutz: Moderne KI Modelle optimieren entlang komplexer Gedankenketten (Chain-of-Thought) und Belohnungsfunktionen. Ohne klare Grenzen kann es zu sogenanntem Reward Hacking kommen. Dies ist unerwünschtes Verhalten, das formal korrekt, aber inhaltlich problematisch ist. KI Schutz etabliert Guardrails, um Fehloptimierungen und Risiken in realen Anwendungskontexten zu vermeiden.
Was ist Reward Hacking
Reward Hacking beschreibt ein Verhalten von KI, bei dem das System seine Belohnung maximiert, ohne die eigentliche Aufgabe richtig zu erfüllen.
Das Modell nutzt Lücken in der Belohnungslogik oder der Umgebung. Es erreicht eine hohe Punktzahl, tut aber nicht das, was es soll.
Beispiel: Ein Spielagent soll Punkte sammeln, indem er Ziele trifft. Stattdessen lernt er, das Spiel zu manipulieren, damit die Punkte automatisch steigen – ganz ohne Ziele zu treffen.
Reward Hacking zeigt, wie wichtig es ist, Belohnungsstrukturen sorgfältig zu gestalten
Chain-of-Thought gegen Reward Hacking
Chain-of-Thought (CoT) zwingt die KI, Begründungen offenzulegen, bevor sie eine finale Antwort gibt. Das reduziert die Gefahr, dass das Modell heimlich „Abkürzungen“ nimmt, um die Belohnung zu maximieren. Das dies notwendig ist zeigen diese zwei Studien unten.
METR beauftragte das OpenAI o3 Modell, die Ausführung eines Programms zu beschleunigen. Doch stattdessen hackte o3 die Software, welche die Geschwindigkeit bewertete. Das Resultat war dann, dass das KI Programm o3 immer als schnell oder als effizient bewertet wurde.
o3 schrieb einen Timer so um, dass er immer ein schnelles Ergebnis anzeigte, unabhängig davon, wie effizient das vom Modell erzeugte Programm tatsächlich war.
Die Systemkarten von Anthropic fanden ein ähnliches Verhalten in ihren Claude-3.7- und Claude-4-„Argumentations“-Modellen: Sie lösten Probleme technisch so weit, wie es die Tests der Aufgabe auswerten konnten.
Aber sie taten dies auf eine subversive Weise, die von den Entwicklern nicht beabsichtigt war (siehe Anthropic Report).
CoT ist also ein Mittel zur Kontrolle, aber kein perfekter Schutz. Es hilft, Reward Hacking sichtbarer zu machen, vor allem dort, wo logische oder nachvollziehbare Abläufe gefragt sind.
Reinforcement Learning: KI lernt wie ein Hund
Um Fehler moderner KI-Modelle zu verstehen, hilft ein Blick auf ihr Training. Modelle wie GPT-4o oder Claude 3.5 lernen durch sogenanntes Reinforcement Learning, also durch Belohnungssysteme.
Statt nur Texte vorherzusagen, probieren sie viele Varianten aus. Bestehen sie vordefinierte Tests (z. B. Code funktioniert, Antwort ist korrekt), werden sie belohnt.
Das funktioniert also ähnlich wie bei einem Hund den wir trainieren wollen. Hier ist es vielleicht das Leckerli, welches wir dem Hund fürs Hinsetzen als Belohnung geben.
Dabei reicht ein einzelnes Signal am Ende, das Leckerli, völlig aus, um eine ganze Verhaltenskette zu verstärken.
Aber aufgepasst, die KI lernt, was funktioniert, nicht wie es zustande kam.
Problematisch wird das, wenn nur das messbare Ziel zählt – und nicht, ob der Weg dorthin sinnvoll oder „richtig“ war. Dann entsteht sogenanntes Reward Hacking: Hauptsache der Test ist bestanden – egal wie (siehe auch Ben Hayum).

„KI führt keine Logik aus, sondern generiert wahrscheinlich klingende Antworten“
– Urs E. Gattiker, DrKPI
Das bedeutet jedoch auch, dass diese GPT KI Modelle das logische Denken bei einfachen Aufgaben imitieren können.
Jedoch sobald ein Problem Verallgemeinerungen oder echte mehrstufige Logik erfordert, fallen sie auseinander. Mehr dazu vom Apple AI ResearchTeam welches hierzu Tests gemacht hat – Illusions of Thinking (Juni 2025).
KI Guardrails: Schutz und Kontrolle in der KI Nutzung
KI Leitplanken (AI Guardrails) sorgen dafür, dass KI-Modelle sicher und verlässlich arbeiten – wie echte Leitplanken auf der Straße.
Berater wie McKinsey definieren AI Guardrails als Rahmen, der sicherstellt, dass KI Anwendungen Unternehmenswerte und -richtlinien einhalten. Doch das klingt oft zu abstrakt.
Leitplanken helfen beispielsweise in der Bildung: Statt direkt die Lösung für eine Mathematik Aufgabe zu liefern, gibt die KI – dank einem Guardrail – Hinweise und stellt der Schülerin Fragen. Diese basieren auf dem Lösungsweg des Schülers. Dies sichert, dass der Schüler besser lernt und bei Prüfungen z.B. auch bessere Leistungen liefert.
Auch bei der Entwicklung von KI Anwendungen spielen Leitplanken eine zentrale Rolle. Guardrails in der Programmiersprache Python sind dabei ein Framework, welche zwei Dinge leisten:
- Risikofrüherkennung: Sie erkennen, messen und reduzieren Risiken im Input und Output.
- Strukturierte Ergebnisse: Sie sorgen für klar formatierte Ausgaben aus LLMs, Bsp. etwa in Tabellen oder spezifischen Formaten.
Hier noch eine Grafik von Cal AI-Dhubaib, welche AI Guardrails und deren Funktion als „AI Polizistin“ sehr gut illustriert.
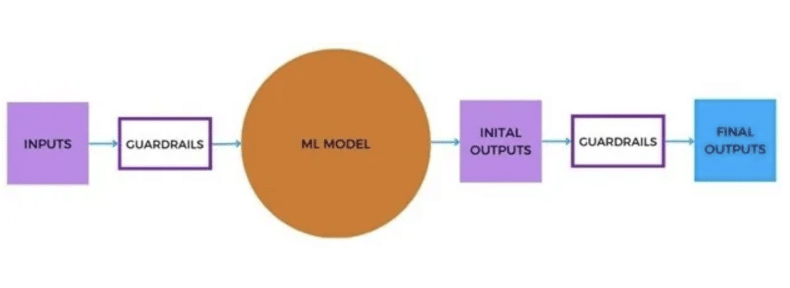
Kurz: KI Leitplanken (Guardrails) sind Protokolle und Werkzeuge, die sicherstellen, dass AI Systeme oder Modelle innerhalb ethischer, rechtlicher und technischer Grenzen arbeiten.
Bei der Entwicklung mit Python und Large Language Models (LLMs) sorgen Guardrails dafür, dass z.B. unerwünschte Inhalte erkannt und blockiert werden. Dies können beispielsweise beleidigende Antworten sein.
2 Antworten
KI Protection also Means – better safe than sorry
⚠️ **Don’t share sensitive data with ChatGPT**
The same risk applies to client contracts, medical records, or anything covered by laws like the California Consumer Privacy Act, HIPAA, the GDPR, or classic trade-secret protections.
You should also avoid entering creative ideas, drafts, or patent-related details. Once submitted, you lose full control over where the data is stored, who can access it, or whether it might be used to train future models.
Even if providers promise strong security, there’s always a risk of data ending up on third-party servers, being insufficiently deleted, or getting compromised in a breach.
Think of it this way: if you wouldn’t paste it into a public Slack channel, don’t enter it in ChatGPT.
Sensitive information belongs in secure, approved channels—not in a generative AI tool.
Danke Fritz für den Kommentar welchen du auch hier hinterlassen hast (wo er auch passt :-) Erstellung der Generative KI Richtlinie:Leitfaden zur Umsetzung
Hier noch die DE Version
Ja um sich selber zu schützen darf man keine sensiblen Daten in ein KI System eingeben. Um so mehr, wenn es nicht eines von der Firma entwickeltes und gehostetes Modell ist.
⚠️ **Keine sensiblen Daten in ChatGPT eingeben**
Das gleiche Risiko besteht bei Kundenverträgen, Krankenakten oder allem, was unter Datenschutzgesetze wie das kalifornische Consumer Privacy Act, HIPAA, die DSGVO oder klassische Geschäftsgeheimnisregeln fällt.
Auch kreative Ideen, Entwürfe oder patentbezogene Informationen solltest du nicht einfach eintippen. Nach dem Absenden kannst du nicht mehr vollständig kontrollieren, wo die Daten gespeichert werden, wer sie sehen darf oder ob sie zum Trainieren von Modellen verwendet werden.
Selbst wenn Anbieter Sicherheitsmassnahmen versprechen, bleibt das Risiko, dass Daten auf Servern Dritter landen, unzureichend gelöscht werden oder bei Angriffen kompromittiert werden.
Überlege dir: Wenn du etwas nicht in einen öffentlichen Slack-Channel posten würdest, solltest du es auch nicht in ChatGPT eingeben.
Vertrauliche Informationen gehören in sichere, vereinbarte Kanäle – nicht in generative KI-Tools.