

Hier werden wichtig Begriffe erklärt
Haben wir was wichtiges vergessen? Ihre Meinung ist für uns massgebend – hinterlassen Sie einen Kommentar unten. DANKE.
- Update 2025-05-31 Weired Bias – Weired Voreingenommenheit / Datenverzerrung mit KI
- Update 2025-06-07 Alibaba führt schon wieder neue quelloffene KI-Einbettungsmodelle ein
Weitere interessante Links
Das Inhaltsverzeichnis rechts bietet ihnen die Möglichkeitm zu den für sie interessanten Definitionen schnell vorzudringen (anklicken und sie sind dort).
- 1. KI FAQ Glossar: KI Begriffe einfach erklärt
- 2, KI FAQ Glossar: 5 Fehlerquellen für einen Algorithmus, etc. (sie sind hier)
- 3. KI FAQ Glossar: Kompetenz, Literacy, Skills Guardrails, etc.
- 4. KI FAQ Glossar: AI Safety | KI Schutz
- KI Wissen kompakt – Strategie, Skills und Trends
Unseren Newsletter anschauen oder noch besser – der 1,000+ Leser:innen Community beitreten:
- sie brauchen Inspiration, Tips, Tools, Compliance Leitfaden – gleich DrKPI Newsletter abonnieren
Liste von wichtiger Terminologie, die jeweils eine kurze Erklärung und möglicherweise eine Verlinkung zu weiteren Erklärungen enthält.
Wichtige KI-Begriffe im KI-Glossar – Überblick
Wir erklären ihnen hier ein paar für sie sehr wichtige KI-Begriffe ohne unnötigen Hokuspokus.
Der Blogeintrag ist der fünfte in einer Serie von Einträgen:
- AI Effektivität und Effizienz – mehr Effektivität mit KI
- AI Fachkräfte Recruiting: DrKPI 3-Phasen Modell
- AI Training: Widerspruch gegen die Verarbeitung personenbezogener Daten – iPhone, Meta, eBay, usw.
- AI 7 Tests für DeepL vs Mistral: Übersetzung + Textbearbeitung
- AI FAQ – Begriffe einfach erklärt (sie sind hier)
- AI Erstellung der KI Richtlinie für Mittelstand: 10 Punkte Vorlage für 2025
Künstliche Intelligenz (KI)
Künstliche Intelligenz (KI) ist der Versuch, menschliche Intelligenz mithilfe von Computern nachzubilden. Sie beschreibt die Fähigkeit von IT-Systemen, kognitive Leistungen zu erbringen, die dem menschlichen Denken ähneln.
Im Kern geht es bei KI darum, auf Basis grosser Datenmengen Vorhersagen zu treffen – etwa zum Verhalten von Konsumenten oder zur automatisierten Erstellung von Texten oder Fotos.
Trotzdem KI viel kann, denken kann sie nicht (siehe Kognition unten). Ein echtes Verständnis für das Thema ist nicht gegeben.
Algorithmus
Ein Algorithmus ist eine Schritt-für-Schritt-Anleitung zur Lösung eines bestimmten Problems oder zur Durchführung einer definierten Aufgabe.
Jede Anweisung innerhalb eines Algorithmus ist eindeutig formuliert und innerhalb eines gegebenen Kontexts ausführbar. Durch die systematische Abarbeitung dieser Schritte kann eine konkrete Aufgabe gelöst werden – beispielsweise die Berechnung einer Wettervorhersage für den nächsten Tag.
Die Grafik unten zeigt das viele Parteien bei der Erstellung und der Nutzung eines Algorithmus beteiligt sind.
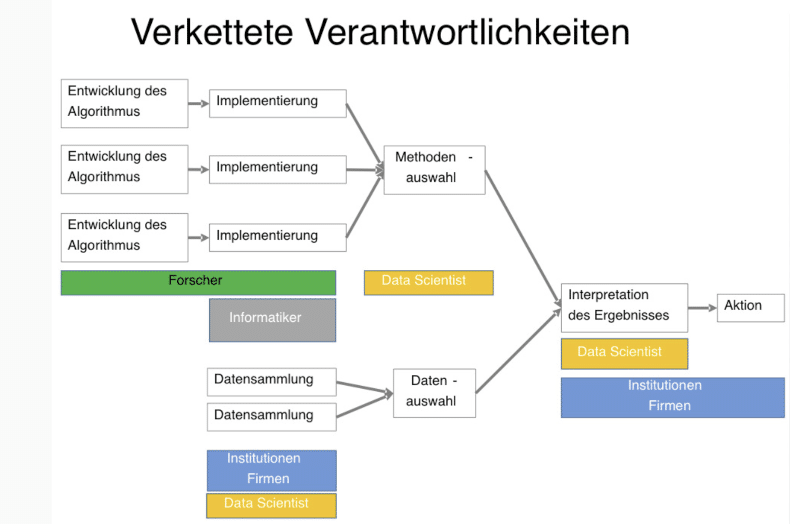
Algorithmus – wie funktioniert es. Mehrere Parteien erstellen den Code für den Algorithmus, sammeln Daten und wählen diese zur Analyse aus.
Dies führt zu einer Kette von Verantwortlichkeiten – 5 Arten von Fehlermöglichkeiten – können beim überprüfen des Algorithmus indentifiziert werden.
Gemäss dem Arbeitspapier – Überprüfbarkeit von Algorithmen – gibt es 5 Fehlerquellen – siehe Tabelle unten
Tabelle – Überprüfbarkeit vom Algorithmus:
5 Fehlerquelllen
| Art der Fehlerquelle | Beispiele für die mögliche Fehlerquelle beim Algorithmus |
|---|---|
| Konzeptionelle Fehler im Algorithmendesign | Wenn zu wenige Faktoren in die Bonitätsprüfung eines Schuldners einbezogen werden. |
| Implementierungsfehler | 2018 führte ein Fehler im Code des Theranos-Bluttestgeräts zu falschen Testergebnissen. |
| Modellierungsfehler | Die Corona-Warn-App in Deutschland hatte anfangs Modellierungsfehler, die die Effektivität und Zuverlässigkeit der Risikodaten beeinträchtigten. |
| Fehlerhafte oder unzureichende Daten – Bias | Gesichtserkennungssoftware zeigt systematische Verzerrungen (Bias) bei der Identifizierung von Menschen mit dunkler Hautfarbe aufgrund fehlerhafter Trainingsdaten. Bei der Überprüfung von 3 Programmen für die Gesichtserkennung – Microsoft, IBM, and Megvii aus China – lag die Fehlerquote bei bei der Bestimmung des Geschlechts von hellhäutigen Männern nie unter 0,8 %. Bei dunkelhäutigen Frauen hingegen stiegen die Fehlerquoten sprunghaft an – auf mehr als 20 % in einem Programm und mehr als 34 % in den beiden anderen. |
| Emergente Phänomene im Zusammenspiel von Algorithmus und Gesellschaft | Facebook-Algorithmen bevorzugen emotionale und kontroverse Inhalte, wodurch Fake News verbreitet werden – ein Beispiel für die Kritik nach der Wahl von Donald Trump 2016. |
Notiz. Tabelle zeigt die 5 Fehlerquellen auf und Beispiele zu jeder dieser möglichen Fehler vom Algorithmus.
Neben den obigen möglichen Fehlern kann es aber auch noch zu rechtlichen Problemen kommen – DSGVO, EU AI Act, usw.
Am 27. Februar 2025 entschied der EuGH, dass Art. 15 Abs. 1 lit. h DSGVO so auszulegen ist, dass betroffene Personen bei automatisierten Entscheidungsprozessen – einschließlich KI-basiertem Profiling im Sinne von Art. 22 Abs. 1 DSGVO – einen Anspruch auf detaillierte Auskunft über die zugrunde liegenden Verfahren haben.
Im konkreten Fall war einem Verbraucher aufgrund eines KI-gestützten Bonitätsscorings ein Vertragsabschluss verweigert worden.
Der EuGH stellte klar, dass dabei auch etwaige Geschäftsgeheimnisse (siehe Richtlinie (EU) 2016/943 was ist ein Geschäftsgeheimnis) offengelegt werden müssen. Gilt, sofern diese Informationen für die betroffene Person relevant sind.
Informationen gelten nur dann als schützenswerte Geschäftsgeheimnisse, wenn sie nicht nur geheim, sondern auch von wirtschaftlichem Wert sind. Dies sah das Gericht als nicht bewiesen an.
KI-Halluzination?
Eine der bekanntesten und beunruhigendsten, aber manchmal auch interessant kreativen Eigenschaften von LLMs ist das „Halluzinieren“ von Tatsachen – oder das Erfinden von Dingen (Update 2025-05-23 – Google Gemini AI weist explicit darauf hin, aber überlässt es den Nutzern damit umzugehen).
Künstliche Intelligenz erzeugt also verzerrte Informationen, die von der Realität abweichen oder keine sachliche Grundlage haben.
KI-Halluzinationen können beispielsweise auftreten, wenn grosse Sprachmodelle (LLMs), denen KI-Chatbots zugrunde liegen, als Reaktion auf Benutzeraufforderungen („user prompts“), falsche oder verdrehte Informationen erzeugen.
Machine Learning – Maschinelles Lernen
Maschinelles Lernen, Deep Learning und neuronale Netze sind Teilbereiche der künstlichen Intelligenz.
Maschinelles Lernen wurde in den 195oer Jahren vom Arthur Samuel definiert als das „Studiengebiet, das Computern die Fähigkeit verleiht, zu lernen, ohne explizit programmiert zu werden“.
Im Gegensatz zur klassischen Programmierung („Software 1.0“), bei der genaue Anweisungen nötig sind, erkennen Machine Learning Algorithmen die möglichen Muster in Daten. Sie können daraus Vorhersagen ableiten und somit z. B. neue Fotos, Texte oder Musik generieren.
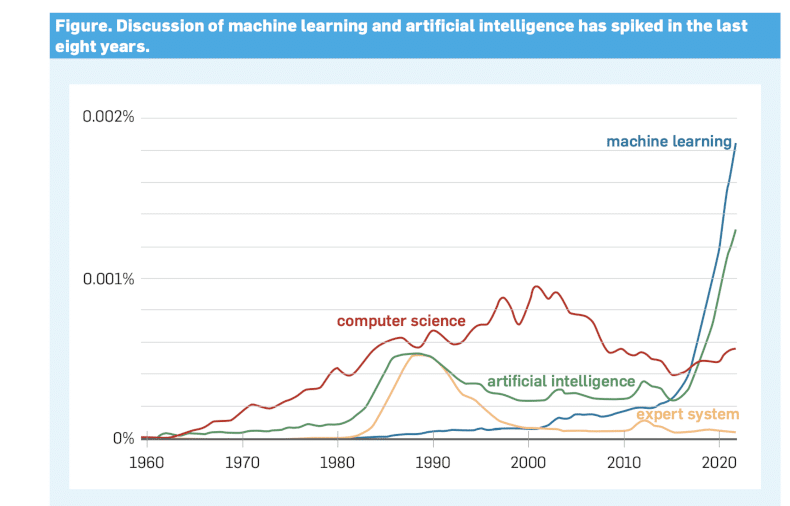
KI-Begriffe im Wandel: Seit 2015 hat die Diskussion über Machine Learning im Netz stark zugenommen. In den 1990er-Jahren dominierten hingegen Expertensysteme und Computer Science mit AI-Bezug die Fachwelt und Schlagzeilen – Artificial Intelligence Then and Now Feb. 2025.
Welche Funktionen erfüllt ein maschinelles Lernsystem?
Ein maschinelles Lernsystem übernimmt in der Regel drei zentrale Funktionen:
- Deskriptiv (beschreibend): Es analysiert vorhandene Daten, um vergangene Ereignisse zu erklären.
- Prädiktiv (voraussagend): Es prognostiziert zukünftige Entwicklungen auf Basis historischer Daten wie eine Wettervorhersage.
- Präskriptiv (vorschreibend): Es leitet aus den Daten konkrete Handlungsempfehlungen ab.
Deep Learning
Deep Learning ist die Entwicklung von Deep-Learning-Algorithmen, die zum Trainieren und Vorhersagen von Ergebnissen aus komplexen Daten verwendet werden können.
Deep-Learning-Systeme bestehen aus neuronalen Netzen und stellen einen Teilbereich der KI dar.
Deep Learning ist auch mit Datenwissenschaft verbunden, denn ohne diese könnten wir die Daten nicht analysieren um zu lernen.
Data Science ermöglicht zahlreiche Anwendungen und Dienste, die Prozesse automatisieren – sowohl analytische als auch physische – ganz ohne menschliches Zutun.
Erst dadurch werden Technologien wie digitale Assistenten, sprachgesteuerte Fernbedienungen, die Erkennung von Kreditkartenbetrug, autonomes Fahren und generative KI realisierbar.
Ein Beispiel für Deep Learning ist die automatische Bilderkennung.
KI kann viel … aber nicht denken. Ein echtes Verständnis für das Thema ist auch mit Deep Learning nicht gegeben.
Anstatt liefert KI ein Ergebnis, das auf dem basiert, was statistisch am wahrscheinlichsten ist. Die gute Nachricht: Der Mensch bleibt gefragt, in der Einordnung, im Ziel, aber auch im Feingefühl.
Neural Network – neuronales Netz
Künstliche neuronale Netze bilden das Herzstück eines Deep-Learning-Systems und gehören zum Maschinellen Lernen, einem Teilbereich der KI.
Künstliche neuronale Netze ist das dominierende Modell das beim Machine Learning (ML) angewandt wir.
Ein neuronales Netz ist die grundlegende Technologie hinter dem Deep Learning. Es besteht aus zahlreichen miteinander verbundenen Knoten – auch Neuronen genannt – die in mehreren Schichten organisiert sind.
Diese Knoten verarbeiten Informationen gemeinsam und passen sich dabei flexibel an. Sie tauschen Rückmeldungen über die erzeugten Ergebnisse aus, lernen aus Fehlern und verbessern sich fortlaufend.
Dank dieser Fähigkeit kann ein neuronales Netz Millionen von Bildern analysieren und dabei lernen, Objekte wie Katzen, Autos oder Gesichter zuverlässig zu erkennen.
Machine Translation – Maschinelle Übersetzung
Bei der maschinellen Übersetzung überträgt ein Programm einen Text von der Originalsprache in die Zielsprache.
Es gibt kein einheitliches Verfahren für alle Arten der maschinellen Übersetzung. Wie ein System einen Text übersetzt, hängt von der jeweiligen Methode der maschinellen Übersetzung ab (z.B. rule-based, statistical oder neural-based translation).
Der Hauptunterschied zwischen computergestützter Übersetzung (CAT) und maschineller Übersetzung besteht darin, dass bei der computergestützten Übersetzung die eigentliche Übersetzungsarbeit von Menschen durchgeführt wird.
Maschinelle Textverarbeitung ist eine eigentliche Erfolgsstory, welcher überraschenderweise wenig Beachtung geschenkt wird.
Beim maschinellen Übersetzungen gibt es 2 wichtige Daten: 1954 und 2016,
Mit dem Georgetown-IBM-Experiment im Jahr 1954 begann die automatisierte Textverarbeitung, langsame, aber stetige Fortschritte zu verzeichnen. Zu dieser Zeit dominierten strukturelle, regelbasierte Systeme, die sich auf grammatikalische Strukturen stützten.
Dies änderte sich 2016, als Google begann, statistische Modelle und neuronale maschinelle Übersetzung einzusetzen.
Hier unten erklären was mit KI vielleicht noch nicht klappt oder ihr womöglich Kopfzerbrechen bereitet.
Open Source KI – China im Vormarsch
Open Source bezieht sich auf Software, deren Quellcode für Benutzer und Entwickler zur Nutzung und Modifikation frei zugänglich ist.
Im Gegensatz zu proprietärer Software wird Open-Source-Software in einer öffentlichen, kollaborativen Umgebung entwickelt und der Allgemeinheit kostenlos zur Verfügung gestellt.
🚀 Open Source KI – wer ist die Schönste im Land? 🚀
Qwen 3, DeepSeek: Open Source KI
Qwen 3, eines der leistungsstärksten neuen Modelle, kletterte kürzlich an die Spitze der LiveBench-Rangliste.
Diese vergleicht AI-Modelle für Aufgaben wie Mathematik, Codierung und Datenanalyse.
Qwen 3, das KI-Modell, das #Alibaba zur öffentlichen Nutzung freigegeben hat, ist ein Beispiel dafür, wie die offene Entwicklung den Zugang zu leistungsstarker KI erweitert.
Update 2025-06-07: Die Qwen3 Embedding-Serie welche Alibaba 2025-06-06 Freitag auf den Markt brachte, unterstützt über 100 Sprachen, einschliesslich Programmiersprachen.
Ein weiteres bemerkenswertes offenes Modell ist natürlich das R1 von #DeepSeek.
PS. Du kannst auf Qwen https://qwenlm.ai/ ein kostenloses Konto erstellen und loslegen.
Ich brauche neben Qwen auch öfters Mistral und ChatGPT.
Probiere es aus.
PS. Scott Galloway las auf der OMR in Hamburg gewissermassen die Teeblätter für 2025 – und sieht OpenAI und Nvidia als klare Gewinner im KI-Bereich (2025-05-13 Romina Haller auf LinkedIn).
Doch diese Annahme basiert darauf, das die Gewinner hier alle Dinge einheimsen. Doch was ist wenn „winner takes it all“ nicht mehr wichtig ist?
China hat die Strategie:
If you cannot win the race, make winning irrelevant.
Wenn du das Rennen nicht gewinnen kannst, dann mach das Siegen bedeutungslos.
Unternehmen im Silicon Valley sind jedoch der Ansicht, dass die Kontrolle über alle Aspekte – von den grundlegenden Modellen bis hin zu den Verbraucherplattformen (vertikale Integration) – ihnen die Dominanz im Bereich der künstlichen Intelligenz sichert.
Doch Unternehmen, die weiterhin in die Skalierung vertikal integrierter KI-Imperien investieren, werden wahrscheinlich zunehmend unter Druck geraten, ihre Rendite zu erzielen.
Andere wie Mistral (FR) – nicht zu 100 % Open Source – DeepSeek (China), Qwen3 (Alibaba), usw. gewinnen schon heute mit deren Open Source Lösungen immer grössere Marktanteile.
Diese Modelle können vom Nutzer selber angepasst werden, Kosten viel weniger Geld und bieten auch Vorteile was Risiko Management, usw. betrifft.
Qwen3 vs. ChatGPT: Kulturelle Nuancen
Der Test zeigt das Qwen 3 kleine kulturelle Nuancen hat gegenüber ChatGPT. Zum Beispiel ist es bei politischen Fragen sehr zurückhaltend. Einige Auskünfte sind auch für jemand in der Schweiz komisch, ohne das man dies hier erwähnen muss.
Doch man kann es ja. selber auf einem Server hosten, dank Open Source die Limitation im Programm ändern (was einige schon gemacht haben) und voilà. Die Antworten passen eher in unser Verständnis was z.B. die Geschichte oder Taiwan betrifft.
Andere Dinge überraschen. Zum Beispiel wie DeepL (Textübersetzungen) oder ChatGPT liebt es das kleine ß – scharfes s (ein Kleinbuchstabe)m welches weder in der Schweiz noch in Österreich genutzt wird.
Es entfernt das ß nur dann wenn man es auffordert. Dies tue ich normalerweise nicht (auch bei ChatGPT nicht) um Energie zu sparen.
Qwen 3: wie ChatGPT ist es nicht gerade sensibel wenn es um kulturelle Nuancen geht DE vs. CH/AT. Kleines scharfes ß kriegen alle serviert, Jänner gibt es nicht es übersetzt auf Januar auch wenn der Nutzer in Wien ist.
Auch ein Nutzer aus Österreich bekommt nicht Jänner serviert im Text sondern Januar, usw.
Trotzdem, Qwen 3 ist ein sehr interessantes Tool das man neben Mistral Le Chat, DeepSeek, ChatGPT auch testen sollte.
Siehe auch DrKPI zu Qwen 3 auf LinkedIn
„Man kann es jedoch selbst auf einem Server hosten und dank Open Source die Einschränkungen im Programm anpassen (was bereits von einigen gemacht wurde). So erhält man Antworten, die besser mit unserem Verständnis von Themen wie Geschichte oder Taiwan übereinstimmen.“ (von Chat GPT)
Man kann das Open Source Modell Qwen3 selbst auf einem Server hosten. Dann ist es möglich, die Einschränkungen im Programm anzupassen, was einige Nutzer bereits gemacht haben. Danach gibt es Antworter, die besser unserem Politik- und Geschichtsverständnis entsprechen, wie z.B. im Fall Taiwan (von DrKPI).
Welcher Paragraph uns am Besten gefällt ist sicherlich auch Geschmackssache, sie sind sich aber ähnlich. Doch ich bevorzuge meine Version. Trotzdem, beide Programme sind eine grosse Hilfe, wenn wir Paragraphen umformulieren wollen. Meistens gibt es dann am Schluss eine von mir nochmals umgeschriebene Version die ich für den Blog oder das Dokument nutze.
Siehe unseren Text unten und die umgeschriebene Version von Qwen 3 – ähnlich wie was ChatGPT-4 liefert (siehe oben kursiver Paragraph).
Qwen3 – Politik und Geschichte – wenn das Open Source Qwen3 auf einem eigenen Server gehostet wird, kann man die Restriktionen ändern. Aber auch so funktioniert es recht gut auch wenn die Statements nicht der Linie der Partei entsprechen.
Marktanteile: Wer dominiert den Markt?
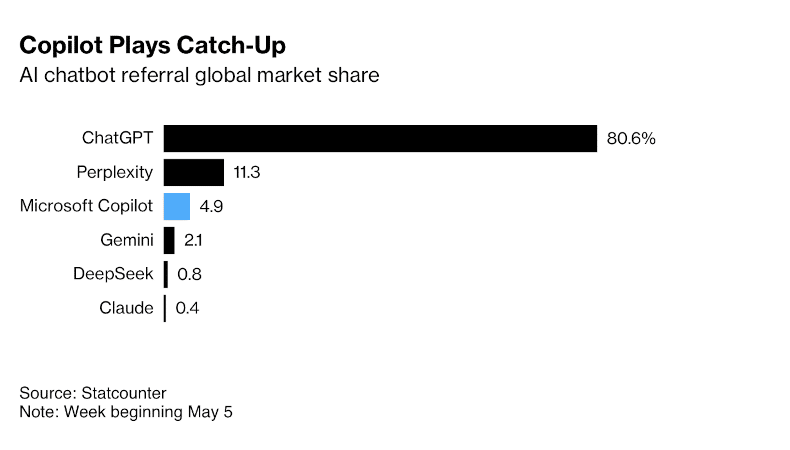
Marktanteile LLMs in der ersten Woche vom Mai 2025: Wie die Grafik unten von Bloomberg zeigt, der Leader ist ChatGPT mit 80.6%.
Weit dahinter kommt Perplexity mit 11.3%, Microsoft Copilot hat 4.9% und Gemini 2.1% vom Markt.
China’s Open-Source Überraschung DeepSeek hat 0.8% und Claude folgt mit 0.4%
Inwieweit Qwen 3 hier eindringen kann wissen wir in etwa 2 Monaten.
PS. Microsoft Copilot und KI-Chatbots wie ChatGPT, Gemini, Claude und DeepSeek werden alle von LLMs (Large Language Model(s) angetrieben. Sie dienen jedoch unterschiedlichen Zwecken und sind auf unterschiedliche Nutzerbedürfnisse ausgerichtet.
ChatGPT ist ein universelles KI-Tool für kreative und individuelle Aufgaben. Der Fokus von Copilot ist die Arbeit von Programmierern mit Microsoft-Tools zu optimieren. Trotzdem Copilot Microsoft and der Microsoft Github CoPilot haben wiederum einen anderen Fokus.
Weiterer Chart – DeepSeek Nr. 2 – Website Nutzung AI ChatBot – Grafik here – Kommentar Noah Karrer.
ChatGPT hat bisher in jedem Monat des Jahres seine eigenen Verkehrsrekorde gebrochen und erreichte im April stolze 780 Millionen Besuche von amerikanischen Nutzern, während die webbasierten Versionen anderer KI-Bemühungen noch nicht einmal annähernd so viel Dampf machen konnten.
DeepSeek, Claude, Perplexity and Grok schafften in den USA „nur“ 90 Millionen Site Visits. Im Vergleich zu ChatGPT 780 Mio eher „wenig“.
Kann KI lernen zu denken, bevor es antwortet? Kognition – Reasoning
Wie oben erklärt kann KI nicht denken wie der Mensch, d.h. auch eine Begründung für eine Entscheidung kann das System nicht liefern.
Hier unten besprechen wir einige Faktoren die beim KI noch weiter entwickelt werden müssen um seine Leistungen zu verbessern.
Was ist Kognition?
Kognition bezeichnet die geistigen Fähigkeiten des Menschen, die mit Wahrnehmung, Lernen, Erinnern, Denken und Wissen verbunden sind.
Ein wesentliches Merkmal: Menschen können ihre Entscheidungen begründen (Reasoning).
KI schafft dies noch nicht (siehe unten: System 1 und System 2 Kognition). Das bedeutet, KI muss noch einiges lernen bevor diese sow wie Menschen denken kann.
Was ist System 2 Kognition?
Der führende Ansatz in der KI basiert auf traditionellen neuronalen Netzen.
Neurale Netzwerke orientieren sich am „System 1“ der Kognition – also schnellen, intuitiven Antworten, wie etwa bei der automatischen Gesichtserkennung.
Menschen nutzen zusätzlich die „System 2“ Kognition. Diese beinhaltet interne Überlegungen und ermöglicht leistungsfähige Formen des Denkens.
Beispiele der System 2 Kognition sind das Lösen eines mathematischen Problems. Ebenfalls die detaillierte Planung eines Auftrages ist System 2 Kognition.
Als Menschen beherrschen wir System 1 und System 2 Kognition, sodass wir Wissensbestände auf kohärente, aber neuartige Weise kombinieren können.
Die KI beherrscht System 1 Kognition.
2 zentrale Schwächen der KI
Die „System 2“-Kognition ermöglicht es uns, Wissensbestandteile auf kohärente, aber neuartige Weise zu kombinieren. Es erlaubt uns aber auch, Entscheidungen nachvollziehbar begründen zu können (Begründung auch „reasoning“ genannt).
Dieses Fehlen von System 2 Kognition nimmt der KI die Fähigkeit ihre Entscheidungen zu begründen. Dies führt zu zwei zentralen Schwächen:
- Mangelnde Kohärenz – also der fehlende logische Zusammenhang in Antworten, was besonders in wissenschaftlichen Kontexten wichtig ist.
- Schwierigkeiten bei langfristiger Planung – entscheidend für autonome Agenten, etwa bei Online-Bestellungen oder Reisebuchungen.
Wenn ChatGPT die Aussage subtil abändert, um sich als AI Tool besser darstellen zu können. Auch AI Tools „wissen“ sich zu verkaufen. Doch dies macht deren Arbeit nicht besser, eher schlechter.
Die Lösung dieser beiden oben genannten Schwächen von KI – Mangelnde Nachvollziehbarkeit und schwache Planungskompetenz – würde den Weg für viele neue KI-Anwendungen ebnen (siehe auch Bengio, 2024-11-20).
Warum ist KI weder innovativ noch kreativ?
KI kann viel. Es erkennt Muster in grossen Datenmengen und trifft darauf basierende Vorhersagen wie z.B. zum Wetter oder welcher Text besser passt.
Doch auch mit Daten analysieren, automatisieren und Prozesse effizienter machen erreicht KI kein echtes Verständnis für das Thema.
Anstatt liefert es ein Ergebnis, das auf dem basiert, was statistisch am wahrscheinlichsten ist.
Die gute Nachricht ist: Der Mensch bleibt gefragt, in der Einordnung, im Ziel, aber auch im Feingefühl.
Beispiele sind auch Geschichtenerzählen, Beziehungsaufbau und strategischem Denken, alles Dinge wo Menschen unersetzlich sind.
Trotz beeindruckender Leistungen der AI bleibt menschliche Kreativität einzigartig.
KI baut auf Vorhandenem auf gemäss Daniel Brüngger in seiner Präsentation am 8 Mai beim MC Lago – Cyberlago Workshop
Menschen können durch kognitive und kreative Prozesse wirklich Neues – mit Originalität und Tiefgang schaffen.
Verbosity Bias – Ausführlichkeits-Verzerrung
Bedeutet das aufgrund mangelnder Wissensspeicherung Chat-Bots z.B. wiederholende Fragen stellen (siehe auch LLMs als Interviewer führt zu verbosity bias).
Das bedeutet beispielsweise, dass LLMs (Bsp. Chat-Bots) in einer Konversation zuvor gelieferte Informationen vergessen. Dies trägt zu sich wiederholenden Fragen und unnötig wortreichen Interaktionen bei.
Aber auch wenn man eine kurzen Paragraphen eingibt in ein KI eingibt, kommt oft ein längerer Paragraph als Resultat zurück. Länger ist besser, ist oft die Annahme der KI. Doch stimmt oft nicht.
Mann kann dieses Problem aber mit der Aufforderung: „kürzer oder kürzen – verbessern“ manchmal beheben, Doch dann wird die Aussage oft verändert oder falsch, wenn sich das System nicht sicher ist (verbosity compensation – unten).
Verbosity Compensation – Verbositätskompensations-Verhalten
Viele LLMs geben längere Antworten (Verbosity Compensation), wenn sie sich der Antwort weniger sicher sind.
Aber auch wenn man eine kurzen Paragraphen eingibt, kommt oft ein längerer Paragraph als Resultat zurück. Je nach Komplexität des Textes ist die KI unsicher und versucht dies in einer längeren Antworten zu vertuschen.
Weird Bias – Weird Voreingenommenheit, Datenverzerrung
Update 2025-05-31 – Weired bias heisst: Western, educated, industrialized, rich, democratic (westlich, gebildet, industrialisiert, reich, demokratisch) Voreingenommenheit oder Datenverzerrung.
Das Akronym Weired fasst das Wesen der primären Datensatzverzerrung der generativen KI zusammen. Diese Systeme neigen dazu, die Verzerrungen ihrer Trainingsdaten widerzuspiegeln.
Die Daten, welche genutzt wurden, um das Modell zu trainieren, führen zu dieser Art von Voreingenommenheit, welche auf westlichen Werten basiert.
Ein Weired Bias haben z.B. Forscher festgestellt, als sie mit Hilfe von KI-simulierten Stichproben versuchten, das Abstimmungsverhalten von Wählern zu prognostizieren.
Wie stärkt KI unsere Marke?
Wenn KI allgegenwärtig ist, wird es schwierig zu erkennen, wo sie beginnt und endet.
Heute ist KI ein Schlagwort in der Wirtschaft, das Unternehmen nutzen, um sich zu profilieren. Doch oft kommt dies ohne echtes technologisches Unterscheidungsmerkmal für die Produkte der Firma.
KI kann Daten und Automatisierung nutzen, um die Effizienz zu steigern. Doch z.B. beim Erzählen von Geschichten, dem Aufbau von Beziehungen und strategischem Denken sind Menschen unersetzlich.

KI ist überall – NOT: Alle Unternehmen behaupten sie nutzen KI. Ob ein Kugelschreiber KI nutzt oder nicht, interessiert den Kunden kaum – wichtig ist, dass er gut schreibt und angenehm in der Hand liegt.
Ob der Kugelschreiber im Foto KI enthält, ist dem Kunden nebensächlich. Wichtig ist, dass er gut schreibt und gut in der Hand liegt.
Dies zeigt, was immer wir erreichen wollen mit KI, primär sollte es die Customer Journey optimieren helfen oder aber die Funktionen vom Produkt verbessern.
Etwas prägnanter ausgedrückt, im Idealfall tut die KI ihren Job zum Wohle des Kunden oder der Organisation im Hintergrund und unauffällig.
Sie haben noch Fragen oder benötigen Unterstützung bei der Entwicklung einer KI Strategie? Melden Sie sich!
Dieser Artikel wurde von Redakteuren geschrieben aber teilweise mit Hilfe von KI optimiert. Danach wurden zusätzliche Texten von Mitarbeitern von DrKPI eingearbeitet und Korrekturen am Text vorgenommen. Lesen Sie unsere KI Richtlinie hier. Der DrKPI Blog hält sich an die KI Richtlinie von DrKPI CyTRAP Labs. Unser Team nutzt generative KI zur Ideenfindung und Inhaltserstellung, veröffentlicht jedoch keine Inhalte ohne gründliche Überprüfung durch einen Redakteur:in und Expertin für das Thema. Alle KI-generierten Inhalte sind zur Transparenz deutlich gekennzeichnet. Es gibt auf unserer Website keine vollständig KI-generierten Inhalte.
Partner mit DrKPI® CyTRAP Labs: Messen was zählt
Wir bieten kompetente Entwicklung und Implementierung von:
- KI-Engineering (EU KI Verordnung, Beratung, Audit, Implementierung, Rekrutierung),
- KPI für digitales Marketing, und
- Vulnerability Disclosure Program (VDP) & GDPR Compliance.
Unsere Strategie: Minimale Ressourcenbelastung, optimierte Prozesse, gezielte KPIs und gesicherte Compliance.
Tools wie DrKPI® PageTracker und KPI AI AuditLight sorgen für innovative Lösungen
Partner with DrKPI® CyTRAP Labs: Measure what matters
We provide expert development and implementation of:
- AI engineering (EU AI Act, Advisory, Audit, Implementation, Recruiting),
- KPI for Digital Marketing, and
- Vulnerability Disclosure Program (VDP) & GDPR Compliance.
Our strategy: Minimal resource strain, optimized processes, targeted KPIs, and assured compliance.
Tools like DrKPI® PageTracke and KPI AI AuditLight drive innovative solutions.
Video: AI Verbreitung braucht kostengünstige Chips
Die weitere Verbreitung von AI in unserem Alltag ist abhängig von Chips im Nanoformat. Das bedeutet, diese müssen klein sein, leicht und so billig, dass deren Preis überhaupt nicht mehr ins Gewicht fält.
Die Produktion is jedoch global wie das Image unten zeigt.
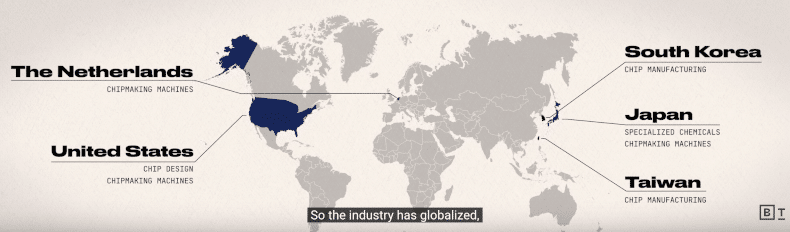
AI ist abhängig von Chips im Nanoformat – leicht, ganz klein und immer billiger sowie effizienter was Energieverbrauch betrifft.
Das hat Prof Chris Miller (Fletcher School of Law and Diplomacy) in einem Video von ca. 14 Min (lohnt sich ganz anzugucken) erklärt.
Dank geht an Naude van der Merwe von CarSalesPortal der das Video unten in seinem Kommentar erwähnt.
Offenlegung: Die Autorin / Bloggerin weist darauf hin, dass einige der erwähnten Organisationen Kunden von CyTRAP Labs GmbH sind und / oder DrKPI® Services und Produkte abonniert haben / beziehen.
8 Antworten
Super Erklärungen, hier meine Frage:
LinkedIn Algorithm Report 2025
Seit Jahren liefert Richard van der Blom diese Insights darüber, wie das Business-Netzwerk funktioniert.
Aber wie weiss er wie das funktioniert, schaut er sich den Algorithmus an?
Oben müssen wir wohl – Algorithmus – auch definieren. Kommt.
ANTWORT 1. Allgemein
Danke für die Frage Peter.
Gemäss dem Report soll das Ergebnis für Unternehmensseiten deprimierend sein. Sichtbarkeit in den Feeds zu erhalten sei immer Schwieriger.
Hier der Link zum Report (anklicken)
ANTWORT 1. Speziell
Die meisten Antworten sind in diesem Report auf ganz wenig Daten abgestützt.
Wo immer Richard van der Blom kann, holt er sich die Daten von den Seiten…. aber das sagt nicht wie der Algorithmus funktioniert.
Um das zu wissen müsste man sich den Algorithmus – Linie für Linie von Code – einmal anschauen. Eine Riesenarbeit die Wochen dauern würde.
Dabei gibt es auch noch Menschen die in die Sachen eingreifen.
Es gibt so viele Faktoren wie Zeitpunkt wo wir posten, wer sieht es zuerst und klick/kommentiert/liked usw.
Nur wenn man für die einzelnen Faktoren kontrolliert kann man auch eruieren, was genau welche Effekte auf die Interaktionen Einfluss nimmt.
Communitymanagement ist so eine Lotterie – nicht ohne Grund haben wir unsere grosse Gruppe auf LinkedIn (anklicken)chon vor fast 10 Jahren geschlossen.
ANTWORT 3. Algorithmus 5 Fehlerquellen
Weil wir bei LinkedIn oder auch Facebook, etc. die Daten nicht überprüfen können, ist es schwierig zu wissen ob irgendwelche Fehler beim Erstellen des Algorithmus eine Rolle spielen.
Ebenfalls ist klar, dass der Algorithmus von Personen verfasste Inhalte oder auch Kommentare / Likes bevorzugt…
Erklärung gibt es weiter oben: Algorithmen: 5 Fehlerquellen die einer Überprüfung unterzogen werden müssen – anklicken
Hi Urs
Prof Chris Miller author of „Chip War“ makes some interesting observations here.
https://www.youtube.com/watch?v=foYWzdvajvo.
➡️ Editor: Built in to view in Blog above click here to view
Regards
Dear Naude
Thanks so much for this link. Amazin how the chip industry is global and what some of these chips cost USD 34 Mio a piece…. to get things working. The movie takes 14 minutes but is worth watching. Really informative.
Thanks for sharing Naude…. one of many screenshots one could take below… but I recommend watching.
Hallo Urs,
interessanter und leicht verständlicher Artikel.
Gerade der Absatz zu Open Source KI hat mir sehr gefallen.
Verblüffend wie gut Qwen3 im Vergleich zu o1 von Openai abschneidet und doch auf wesentlich kostengünstigerer Hardware betrieben werden kann.
Meiner Meinung nach sollten sich durch solche Open Source Lösungen immer mehr Unternehmen unabhängig von den großen Plattformen machen, um ihre eigene digitale Souveränität zu bewahren.
Liebe Grüße
Noah
Lieber Noah
Vielen Dank für diesen Kommentar. Ja Open Source ist hier schon sehr gut denn es hilft uns die Dinge selber zumindest teilweise zu programmieren.
Ich finde es auch schlecht für uns Nutzer, dass ChatGPT so dominant ist. Trotzdem, beeindruckend ist das DeepSeek kostengünstig ist.
Dutzende von Millionen haben den Chatbot DeepSeek ausprobiert, der angeblich zu einem Bruchteil der Kosten des Flaggschiffmodells von OpenAI gebaut wurde.
Dennoch sind die monatlichen Besucherzahlen (aus den USA) – see Grafik unten – gegenüber dem Spitzenwert von 43 Millionen im Februar zurückgegangen wie die Grafik unten zeigt.
Mehr Infos here: Perplexity is in talks to raise again, as the battle for second in the AI chatbot race heats up